JavaScript - Download files with chunks
*** IMPORTANT: this demo will only work on Chrome and Edge and only under a secure context (https, ...) ***
Have you ever had to deal with the download of big files, like 2GB or 3GB of file? This could be a challenging problem, because you can't use a web stream, which could seem a good solution, for achieving this. Indeed, with this approach you have to keep all this GBs of data in memory before writing them into the File System. More, you could also receive a connection timeout error if the file is really big or simply your connection is not really performant. So, how could we deal with this problem? The answer is: use chunks for downloading the file.
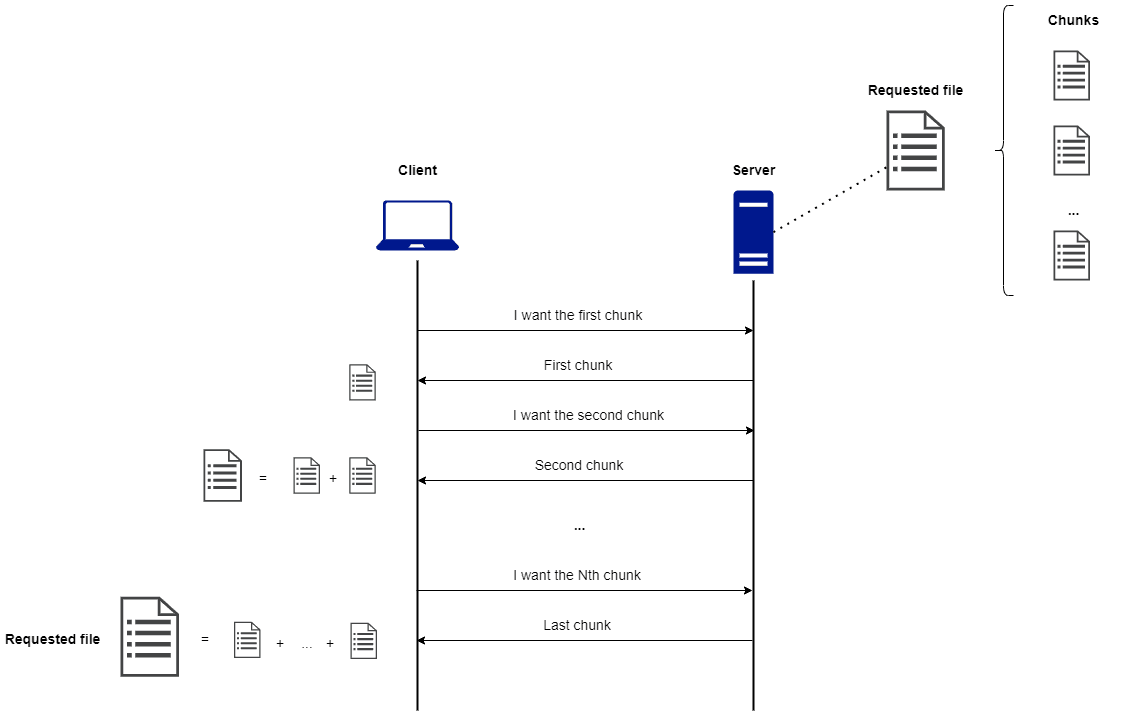
A chunk is a piece of a requested file. When the client collects all the chunks, it is able to recreate the original file merging the pieces. The approach is really simple: imagine to have an API on your server that, given a chunk number it returns the relative chunk. For example /api/getChunk?fileName=bigFileName&chunkNumber=0, will return the first chunk of the file called bigFileName. Each time the client receives a chunk, it adds this to the file it is recreating. After a certain number of chunk requests, the server will respond to the client saying that the chunk that it is going to send will be the last one. At this point, the client has the requested file. The following picture represents this process in a more schematic way.
Now that we have some more information about chunks, let's take a look to a demo. You can find the demo code on this GitHub link. This demo is written in .NET 6 and pure Javascript.
The chunk API
In the demo code, you can find a simple API which, given a file name, an offset and a chunk size, returns the required chunk. I won't discuss this implementation, because this is not the topic of this short paper. Nevertheless, if you want some more information, or you have any doubt or suggestion about this part of the demo, don't exitate to contact me.
The client code
Let's take a look to the client side code. In the ChunkDownload.jsfile under the folder Script in the wwwroot, we have the downloadFile function. This function performs the calls to the API in order to take all the chunks and recreate the original file. It uses a retry logic, in case one of the calls fails, and it also uses a dynamic chunk size, which adapts itself to the available bandwidth.
The first thing we have to do in the function is setting some constants values we will use during the download (the values used are just test values, fit them to your needs):
1// Constants (this values are only for test purposes: change them as you need)
2const MIN_CHUNK_SIZE = 100 * 1024; // 100KB
3const MAX_CHUNK_SIZE = 5 * 1024 * 1024; // 5MB
4const MAX_CALL_ATTEMPTS = 4;
5const PROCESS_DURATION_TIME = 2 * 1000; // 2 sec.- MIN_CHUNK_SIZE and MAX_CHUNK_SIZE represents the lower and upper bound for the chunk size. Setting this bound is important for not overloading the server with a lot of calls which requires little chunks or with few calls which instead require big chunks. These values are the same of the ones set in the API code.
- MAX_CALL_ATTEMPTS represents the max number of retries of a call if this one fails.
- PROCESS_DURATION_TIME represents the desired time in which the call must be completed. This is used for computing the dynamic chunk size.
Once set these constants, we have to open a save file picker in order to let the user choosing the location and the name of the file he is going to download:
1// Open the modal window for letting the user choose the new file's name and destination
2const handle = await window.showSaveFilePicker({
3 suggestedName: fileName
4}).catch(e => console.log('The user closed the SaveFilePicker'));
5
6if (!handle) return;An important aspect to consider is what happens if the users simply closes the save file picker window. In this case an Error is thrown and null is returned, so we must catch this error and then check if handle has a value before going on.
Now we can start with the fetching cycle.
The fetching cycle
Here we are with the heart of the client side code:
1try {
2
3 const md5 = CryptoJS.algo.MD5.create();
4
5 while (true) {
6 if (attempts > MAX_CALL_ATTEMPTS) {
7 throw new Error(`Unable to pefrom the operation: a call failed ${MAX_CALL_ATTEMPTS} times`);
8 }
9
10 const requestBody = { fileName: fileName, offset: offset, chunkSize: chunkSize }
11
12 // Save the time of the request: we'll use it to check how long the request takes and fit the chunk size
13 const timeStart = Date.now();
14
15 let result = null;
16
17 // Retry logic
18 try {
19 result = await fetch('/api/Download/chunk', {
20 method: 'POST',
21 headers: { 'Accept': 'application/json', 'Content-Type': 'application/json' },
22 body: JSON.stringify(requestBody)
23 });
24
25 if (result.status !== 200) {
26 console.log('API call returned HTTP status code: ' + result.status);
27 throw new Error('API call returned HTTP status code: ' + result.status);
28 }
29 } catch (err) {
30 attempts++;
31 result = null;
32 await new Promise(resolve => setTimeout(resolve, (2 ** attempts) * 1000)); // Exponential wait
33 }
34
35 if (result) {
36 // OK now we must read the response body
37 const responseBody = await result.json();
38
39 // Get the decoded binary from response
40 const binary = base64DecToArr(responseBody.data);
41 // Write binary to the file
42 await writable.write(binary);
43 // Update the MD5 with the new binary
44 md5.update(CryptoJS.lib.WordArray.create(binary));
45
46 const newListItem = document.createElement('li');
47 newListItem.innerText = `Required chunk of size: ${chunkSize} bytes, received chunk of size ${binary.length}`;
48 document.getElementById('chunkList').appendChild(newListItem);
49
50 // Get the duration of the process and recompute chunk size
51 const processDuration = (Date.now() - timeStart); // milliseconds
52 chunkSize = ComputeNextRequestChunkSize(processDuration, chunkSize);
53
54 // Update other params
55 offset += binary.length;
56 attempts = 0;
57
58 if (responseBody.md5) {
59 // OK we are at the end: check the MD5
60 const clientHash = md5.finalize().toString(CryptoJS.enc.Base64);
61 if (responseBody.md5 !== clientHash) throw new Error('Unable to verify the MD5');
62 break;
63 }
64 }
65 }
66
67 document.getElementById('statusLabel').innerText = 'Download Completed';
68
69} catch (err) {
70 document.getElementById('statusLabel').innerText = err; // Just for testing purposes
71 writable.truncate(0); // An error occured: we can't delete the file (we should ask the usere to select it again ... Not so good), so we can empty it
72} finally {
73 writable.close(); // This call is really important. Without this the temporary file won't be deleted and the file will left opened
74}The most interesting things here are the retry logic of the calls and the dynamic size of the chunks required.
As you can see, each time the fetch fails, we encrease the attempts counter and we try again the call after an exponential wait with base two. After four attempts we stop trying and we throw an Error. Notice the most external catch: here we call the truncate method on the writable stream. Indeed we can't delete the file, or better, we could but this implies opening a new file picker and ask the use to select the file again. Not a really good user experience!.
Regarding the dynamic size of the chunks, we call the ComputeNextRequestChunkSize at each iteration. Let's analyze the code of this method:
1function ComputeNextRequestChunkSize(processDuration, currentChunkSize) {
2 const newChunkSize = Math.floor((PROCESS_DURATION_TIME * currentChunkSize) / processDuration);
3 if (newChunkSize > MAX_CHUNK_SIZE) return MAX_CHUNK_SIZE;
4 else if (newChunkSize < MIN_CHUNK_SIZE) return MIN_CHUNK_SIZE;
5 else return newChunkSize;
6}This method simply computes this proportion:
newChunkSize : REQUEST_DURATION_TIME = currentChunkSize : requestDuration
in this way we always try to get close to our desideredREQUEST_DURATION_TIME and so the clients with more bandwidth to their disposition will have bigger values of newChunkSize. Instead the ones with less bandwidth will receive lower values. Of course, if the newChunkSize is greather than MAX_CHUNK_SIZE or is lower than MIN_CHUNK_SIZE is brought back into the bounds.
Another important aspect is the decoding from base64 of the response data body. In this case we use a function provided by MDN for handling the "Unicode Problem", which consists in a rewrite of the atob function. You can find the explaination here.
When does the fetching cycle ends?
We must find something for understanding that we have received the last chunk. Why not using the MD5 of the file already received? This way we can even perform a check on the integrity of the file received. Each time we get a chunk, we update the MD5. When the server returns a response body with the field md5 valued we finalize the MD5 computed so far and we check if this is equal to the one received from the server. If they are equal everything is ok, otherwise we throw anError. For computing the MD5 has been used the Crypto-js library
In the end, when the fetching cycle ends, even with an error, we must close the file. This is really important, otherwise the data won't be written to the final file. Indeed the write called on the writable stream firstly writes the data on a temporary file, then, when the stream is closed, it solidifies the data to the final file. You can see this in the following picture:

Conclusions
As you have seen, the chunk technique is really interesting, because it lets you deal with big files without too much difficulty.
The code provided is just a demo, so you can start from it and then fit it to your needs. I hope you liked this short paper! Let me know if you have any suggestion or improvement.
See you!
Links
- https://github.com/MarcoCavallo98/file-chunk-download-js
- https://developer.mozilla.org/en-US/docs/Glossary/Base64#solution_2_%E2%80%93_rewriting_atob_and_btoa_using_typedarrays_and_utf-8
- https://developer.mozilla.org/en-US/docs/Web/API/Window/showSaveFilePicker
- https://developer.mozilla.org/en-US/docs/Web/API/FileSystemFileHandle
- https://developer.mozilla.org/en-US/docs/Web/API/FileSystemFileHandle/createWritable
- https://cryptojs.gitbook.io/docs/